搞分布式数据分析系统,hadoop绝对是不可绕过的一关,所以简单玩了一下,以下是总结。
map reduce
- automatic parallezation
- Fault tolerance
- a clean abstraction for programmers
BSP model : Bulk sychronous parallel
identity reducer?re
基本概念
Apache Hadoop与HDFS
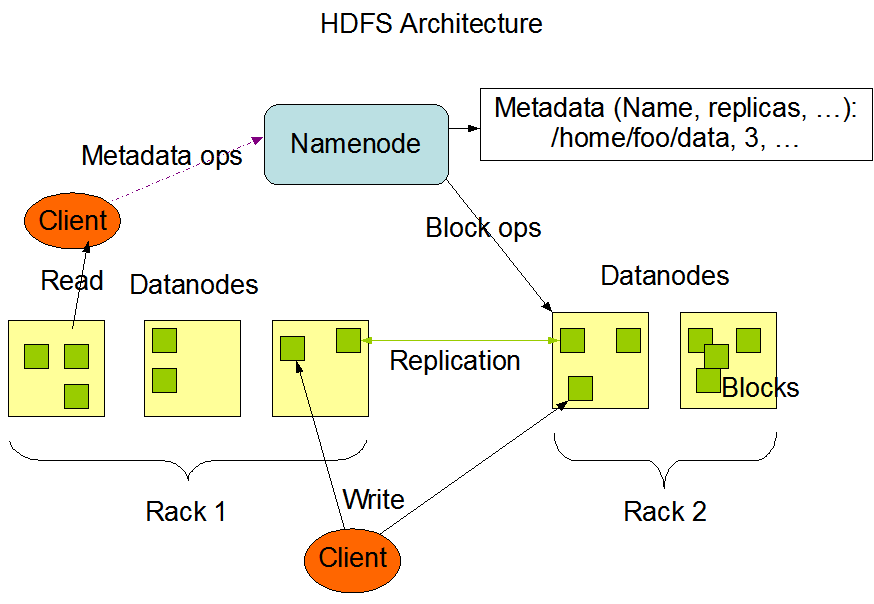
Hadoop是一个大的生态系统,最主要是hdfs和一个基于mapreduce的分布式计算引擎。hdfs就是一个文件系统,在mapreduce的时候(包括用spark的时候)都需要对应文件在hdfs里。
block块:HDFS在物理上是以block存储的,block大小可以通过配置参数(dfs.blocksize)来规定,默认128M,可以减少寻址开销。大文件会被切分成很多block来存,而小文件存储则不会占用整个块的空间。
NameNode:是master。负责管理文件系统的namespace(可以理解是指向具体数据的文件名、路径名这种)和客户端对文件的访问。data path?
(非Yarn)JobTracker:在NameNode上,协调在集群运行的所有作业,分配要在tasktracker上运行的map和reduce任务。
DataNode:是slave。datanode则负责数据的存储。
(非Yarn)TaskTracker:在datanode上,运行分配的任务并定期向jobtracker报告进度。
流式访问:指hdfs访问时像流水一样一点一点过。这样也决定了hdfs是一次写入、多次读取的特性,同时只能有一个wirhter。这样访问方式适合做数据分析,而不是网盘这种。
rack-aware(机架感知):这是hdfs的复制策略。hdfs为了数据可靠一般会将数据复制几份(默认三份)。同一个机架的机器传输速度快,不需要通过交换机。为了提高效率,一台机器的数据会把一个备份放在同一机架(相同rack id)的机器里,另一个备份放在其他机架的机器上。机架的错误率很小,所以不影响可靠性。
hdfs的特点:
- 面对构成系统的组件数目很大,所以对硬件的快速检测错误并自动回复非常重要
- hdfs需要流式访问他们的数据集
- 运行的数据集非常大,一个典型文件大小一般在几G到几T
- 文件访问模型是“一次写入、多次访问”
- 将计算移动到数据附近闭将数据移动到计算更好
Yarn
yarn其实是解决了经典mapreduce中一些问题(例如:jobtracker太累导致的可扩展性问题)的新一代hadoop计算平台。
ResourceManager:代替jobtracker,以后台进程的形式运行。追踪有哪些可用的活动节点和资源,指出哪些程序应该何时或者这些资源。
ApplicationMaster:代替一个专用而短暂的JobTracker。用户提交一个应用程序时,会启动applicationmaster这个轻量级进程实例来协调程序内任务(监视进度、定时向resourcemanager发送心跳数据、负责容错等),计算数据需要的资源并向resourcemanager申请。它本身也是在一个container里运行的,且可能与它管理的任务运行在同一节点上。
Container:是yarn中资源的抽象,封装了某个节点上一定量的资源(如cpu和内存等资源)。它的分配是由applicationmaster向resourcemanager申请的;而它的运行则是applicationmaster向资源所在的nodemanager发起的。
NodeManager:代替tasktracker。拥有很多动态创建的资源Container。容器大小取决于它所包含资源量,而一个节点上的容器数量由配置参数和除用于后台进程和操作系统以外资源总量决定。
基本架构
Hdfs采用了master/slave架构。一个hdfs集群由一个namenode和一群datanodes组成。简单来说,就是hdfs通过namenode暴露出了文件系统命名空间的操作,包括打卡、关闭、重命名文件等等。在这个文件系统对一块数据的操作会映射到具体的datanodes上。
所以一般是一台机器上搭namenode,然后datanode在其他各个机器上。
Hadoop Streaming
java这么规范的东西有人就是不喜欢,非得用python啥的写hadoop,所以就有了hadoop streaming,支持其他语言的hadoop操作。
Haddop Resource Management
hadoop的资源管理进化
基本操作
单节点测试
比较无聊,只是测一下能不能跑,不需要运行什么
1 | cd Cellar/hadoop/3.1.0/libexec |
伪分布式测试(pseudo-distributed)
保证本机已经装好hadoop,java1.8(java9有些函数被废了会报错)
配置本机ssh,确保
1
ssh localhost#mac默认不允许,需要手动去打开
可以运行。注意:mac默认不允许任何机器远程登录,需要到 系统偏好设置 -> 共享 去勾选远程登录。
配置HDFS,包括core-site.xml文件和hdfs-site.xml文件。前者配置用于存储HDFS的临时文件目录和hdsf访问端口,后者确定复制份数
1
2
3
4
5
6
7
8
9
10
11
12
13<!-- core-site.xml -->
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>[$HADOOP_HOME]/tmp</value>
<!--如果无此目录则去mkdir一个-->
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!-- hdfs-site.xml -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>[$HADOOP_HOME]/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[$HADOOP_HOME]/hdfs/datanode</value>
</property>
</configuration>格式化HDFS
1
hdfs namenode -format
成功的话在tmp目录下可以看到dfs文件
启动各个节点
1
2
3
4
5
6
7
8直接启动全部(包括hdfs和yarn)
sbin/start-all.sh
分别启动
hdfs --daemon start NameNode#启动namenode
hdfs --daemon start DataNode#启动datanode
hdfs --daemon start SecondaryNameNode#它是namenode的快照,保证了namenode的更新
用来查看这些节点是否真的启动了在HDFS上创建文件夹及文件
1
2
3hdfs dfs -mkdir /demo#在hdfs上创建demo文件夹
hdfs dfs -ls /demo
hdfs dfs -put test.input /demo#将本地的test.input文件发到hdfs上配置Yarn的mapred-site.xml和yarn-site.xml
1
2
3
4
5
6
7
8
9
10
11
12<!-- mapred-sited.xml -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>share/hadoop/mapreduce/*</value>
</property>
<!-- 如果不加这个property,在后面运行mapreduce任务时会报找不到包 -->
</configuration>1
2
3
4
5
6
7
8
9
10
11
12
13<!-- yarn-site.xml -->
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration运行mapreduce任务
1
hadoop jar hadoop-mapreduce-examples-3.1.0.jar wordcount /demo/test.input /demo-output/
可以到对应文件里查看运行结果