这个礼拜的课都在讲mapreduce,自己也看了google那篇文章,感觉理解了很多,趁着刚学的知识正热乎着,赶紧在这里总结一下。
首先,关于HDFS的内容在另一篇博客中有了比较详细的介绍,这里直接谈MapReduce。
使用MapReduce的目的
用一个工具只有知道他的目的和优点,才能找到最合适的使用场景。简单来说,mapreduce提供了一个自动并行和分布式计算的工具(接口),在大规模集群中性能出众。由于它隐藏了这些分布式系统的细节,所以很多不懂分布式的程序员也可以基于此搭建分布式系统。对于一些web服务器、爬虫、排序算法、机器学习、数据挖掘等都很有用。
MapReduce的架构和运行
这是本文的重点,不多说,直接上图。
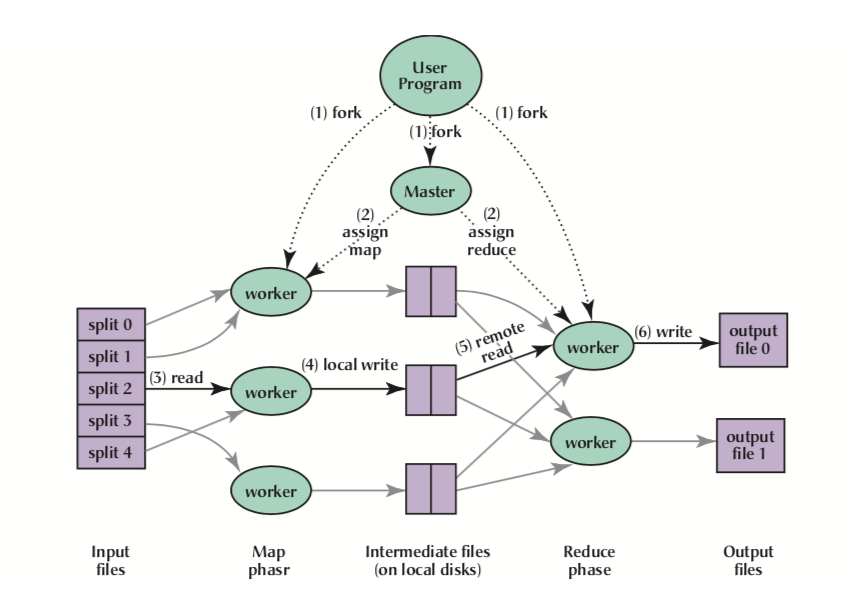
这幅图是直接从论文截下来的,生动的讲述了mapreduce的整个流程:
- 将用户input文件主动分割成成16-64MB大小的块,然后在集群中做一些备份(一般备份3份,其中两份在同一个机架上)
- master发挥作用,将选择一些idle的worker给其分配map或者reduce任务。
- 这时候worker就会去读那些被分割的文件,将一个key/value对读取到用户定义的map函数中。worker在读取这些文件时,会优先读取本地存着的,如果本地没有,选取离它最近的文件,减少网络传输代价。
- map函数会产生一些中间过程数据,然后周期性的通过buffer将它存在本地磁盘上,然后将地址、文件名等信息通知master,这些中间文件通过hash(key) mod R的方式被分成R份(R是reduce worker的数量),master就会将这些块分配给对应的reducer。
- reducer会通过RPC方式读取到这些中间过程数据,然后进行一个排序(shuffle),这个shuffle会让相同value聚在一起。这个很必要,因为不同key会映射到同一个reduce任务上。
- 只有在map全部结束后,reduce才会开始。在reducer中处理这个有序数据时,遇到相同key就会把value放在用户定义的reduce函数中。最终reduce函数会把结果文件输出到这个reduce partition中。
最终得到的结果其实就是part-r-00000这样形式的不同文件。用户没必要把output文件最后聚在一起,如果需要的话,这个结果还可以作为下一轮mapreduce的输入。
在有Combiner后过程的改良
上面的过程是论文中解释的,但现在的程序都用了Combiner,Combiner其实和reduce的代码是一样的,那他是做什么用的呢?
Combiner其实是针对本地的map后的结果进行pre-reduce(或者叫mini-reduce),例如wordcount在map之后大概是(‘a’:1),(‘b’,1),(‘a’,1),(‘c’,1)这样,combiner将local的这些先做一次reduce,变成(‘a’,2),(‘b’,1),(‘c’,1),之后再去shuffle和reduce。
综上mapreduce整个过程分为四步:
Map -> Combiner -> Shuffle -> Reduce
Master节点的任务和结构
对于每个map任务或者reduce任务,都分成三种状态:idel, in-progress, completed。每个任务的这些状态都存在master节点上。
Master节点是作为map任务和reduce任务通信的管道的。master要存储并更新M个map任务产生的M R个块(每个map任务产生R个块)的位置信息、文件名等。即,master承担 O(M+R)个scheduling决策,存储 O(M R)个状态信息。
M:map是的m块数据,R: reduce时的r块数据,W: worker机器的数量;三者关系为:
M > R > W
Worker的容错问题
首先,master出错的话,没啥好说的,直接告诉用户就成。
worker一旦出错,master应该要感知到,有两种策略感知:
Pull模型 :worker通过发送heartbeat给master,master在感知到heartbeat之后在heartbeat response里给worker分配任务。
Push模型:master一直ping worker,当一段时间ping不通后说明worker失败了。
这个时候master会将worker的任务分配给其他的worker去执行。对于执行完的worker,状态会重新标定为idle,表示有资格接受任务。失败的worker也会被标定为idle,同样可以接受任务。
对于在失败的worker上completed的map任务,在其他worker上需要重新执行,因为他们存在本地的中间数据访问不到了。但对于在失败的worker上completed的reduce任务则不需要重新执行,因为他们的结果文件存在了global的文件系统下。
在执行mapreduce时对于一些straggler(落伍者),有两种处理方式:
- Job stealing: 对这个job进行分片,将没完成的部分交给其他的worker完成。
- Speculative execution: master,这时候两个类似竞争的关系,当其中一个结束时,这个task会被标定为completed,同时另一个task将会被放弃。