最近project需要mongo做存储,因此在这里总结一些mongo的东西
基本概念
Mongo是一个开源的文档型数据库,它提供了高性能、高可用和自动扩展的特性。
概念对应关系如下表:
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
| aggregation(group by) | aggregation pipeline | 聚合函数 |
| transactions | transactions | 事物 |
mongo支持包括mongo shell、c++、java、python、php等几乎所有主流语言。只需要下好对应的driver即可,下面的操作我们使用pymongo来完成。
CURD操作
CURD是数据库基本操作。这里用pymongo来创建mongo client。
1 | from pymongo import MongoClient |
Read操作
1 | result = collection.find_one({filter}) |
Update操作
1 | collection.update_one({filter},<{$set}>) |
Create操作
1 | #在这里我读取一个json文件,然后存入数据库中 |
Delete操作
1 | collection.delete_many({filter}) |
Bulk Write操作
1 | from pymongo import InsertOne,DeleteMany,UpdateOne |
Text Search操作
1 | #mongo提供了针对文本内容search的方法,要想使用这个就要先对对应field创建text index |
Replication
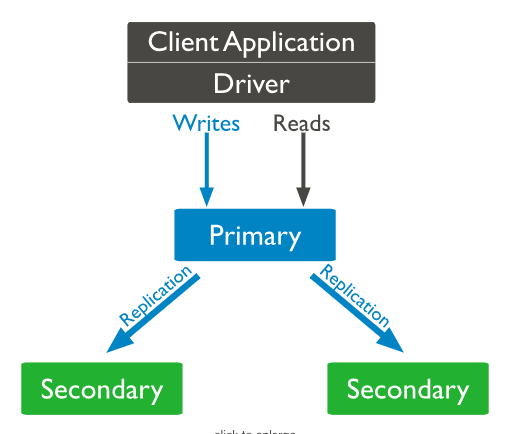
一组replica只指存相同数据的节点集。其中只有一个被认为是primary节点,其他是secondary节点(类似于master-slave)。
只有primary节点可以接受所有的写操作,并且通过{w:”majority”}来确认通知。同时primary会把所有数据操作放在oplog里。
对于secondary节点,他们会备份primary节点的oplog,然后把log里的东西apply到自己的节点上,这样primary上的dataset也就映射到了secondary上。当primary不可用时,secondaries会通过选举决定谁是primary。
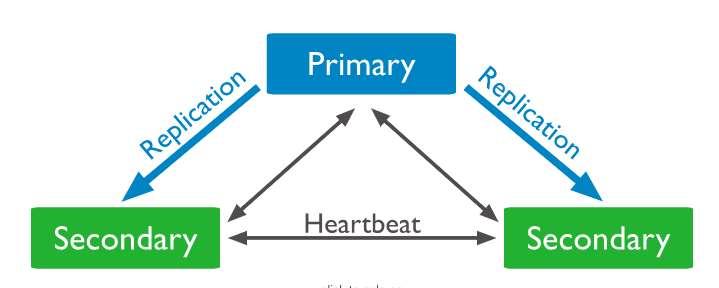
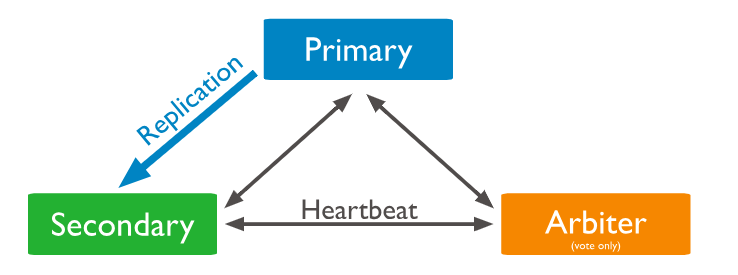
你可以额外增加一个叫arbiter的节点,arbiter不维护任何数据,它通过应答其他节点发出的心跳和选举请求,维护了投票时需要的法定人数。因为它本身不维护dataset,所以它占用的资源很少,也不要单独硬件。所以当节点数为偶数时,可以增加一个arbiter来维护。
Asynchronous Replication
secondary本身异步地从primary复制。完成备份后,即使。
Automatic Failover
当primary在一定时间(configured by electionTimeoutMillis,10s default)不与secondary通信时,有资格的secondary会提名自己参加选举,cluster会试图完成选举并恢复正常功能。
在选举阶段,这个replica set都无法进行写操作,个别secondary如果配置了允许读操作的话还是正常进行的。通常系统会在12s只能判定一个primary不可用并完成选举工作。
Sharding
Sharding是Mongo采用的一种在多台机器上分布数据的方法。对于在大量、高吞吐率的数据在单台服务器上无法承载,有两种方法来扩展机器:
- Vertical Scaling:增加单机的容量、内存,使用更好的cpu等方式。但这种受限于目前可用的技术能力。
- Horizontal Scaling:增加机器的数量,每个机器只要handle一部分数据。比较便宜,但维护和部署基础设施成本较高。
Sharding cluster包含一下组件:
- Shard:每个shard包含总的一个子数据集。每个shard都可以被部署为备用数据集。
- mongos:mongos作为query router,提供了client和sharded cluster之间的借口。
- config servers:储存了metadata和cluster的配置设置。在mongo3.4,其必须被部署为一个备用数据集(CSRS)。
关系组图如下:
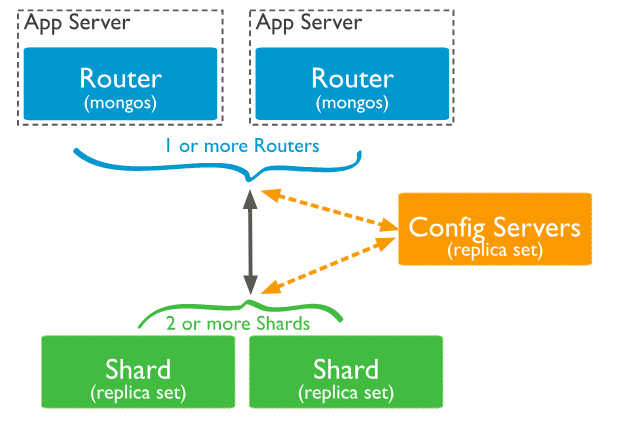
MongoDB从collection层面来分割数据。
Shard Keys
MongoDB是根据shard key来分割一个collection的。shard key是由目标collection中每个document都有的fields或者不变的field组成的。
在分割collection时要选择shard key,分割完后shard key就不能再改变了。
对于非空collection,必须有一个index是以shard key开头的;而对于空collection,MongoDB则会创建一个index。
shard keys的选择会影响sharded cluster的性能、效率、扩展性等问题,它和它背后的index也会影响你的集群可以使用的sharding策略。
Chunks
MongoDB会数据分成一个个的chunks,其中包含了左闭右开的shard key范围。Mongo使用shared cluster balancer来实现在sharded cluster上的不同shards间移动chunks。
Sharded and Non-sharded Collections
每个数据库都可以既有sharded collections又有un-sharded collections。unsharded collection存在数据库的primary shard上。每个数据库都有primary shard。
Connecting to a sharded Cluster
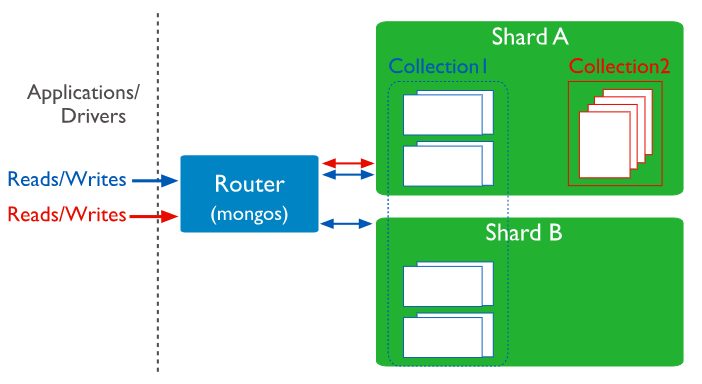
用户通过mongos router来实现和sharded cluster(包含sharded和unsharded collections)的交互。client做读写操作时不能只连接一个shard。
Sharding Strategy
具体来说sharding的方式有两种:
Hashed Sharding
通过计算shard key的hash值来分到不同的chunk中。在使用hashed indexes来处理查询时,client不需要计算hash,这个由MongoDB自动完成。
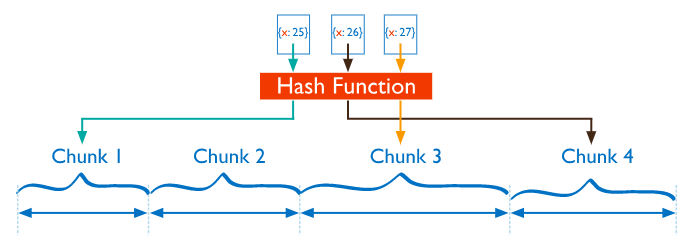
对于那种很接近的shard key(例如单调递增的),hash通常会比较均匀地把他们分到不同的chunk里。这样存在个问题:当我要取一定范围内的数据时,需要从各个不同的chunk里取,造成较大范围的broadcast operations。
Ranged Sharding
把shard key的值分成一定范围区间,然后分配。
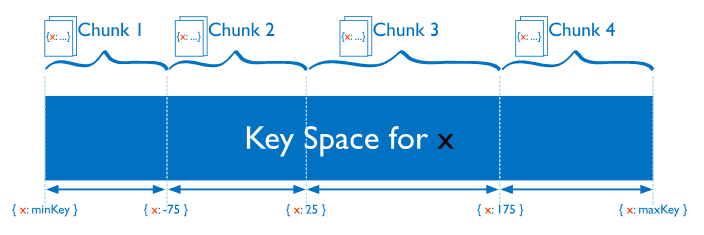
这样相近的shard key实在同一个chunk里的,这样mongos只需要把operation route到包含这些数据的shards。
这个方式很依赖shard key的选择,不理想的话可能造成数据分配不平衡。
Zones in Sharded clusters
在sharded clusters里,可以把几个shard对应到一个zone中,一个shard也可以对应到多个zone里。chunks只在相同zone下的几个shards中转移。
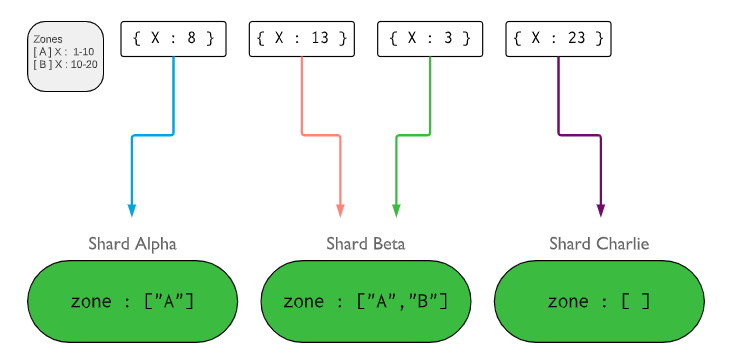
zones存在的目的是提高在大的sharded clusters里数据的本地化程度。