kafka是一个高性能,高可靠性的消息系统,具体来说:
- kakfa维护了不同topics的消息流
- 支持对消息流的发布/订阅
- 通过多服务器备份进行FT
- 高效I/O,batch和compression
- 对消费者和生产者解耦
另外,kafka还提供了消息存储的功能,一定程度上可以当一个分布式存储系统用,它将数据存储在disk上
kafka架构
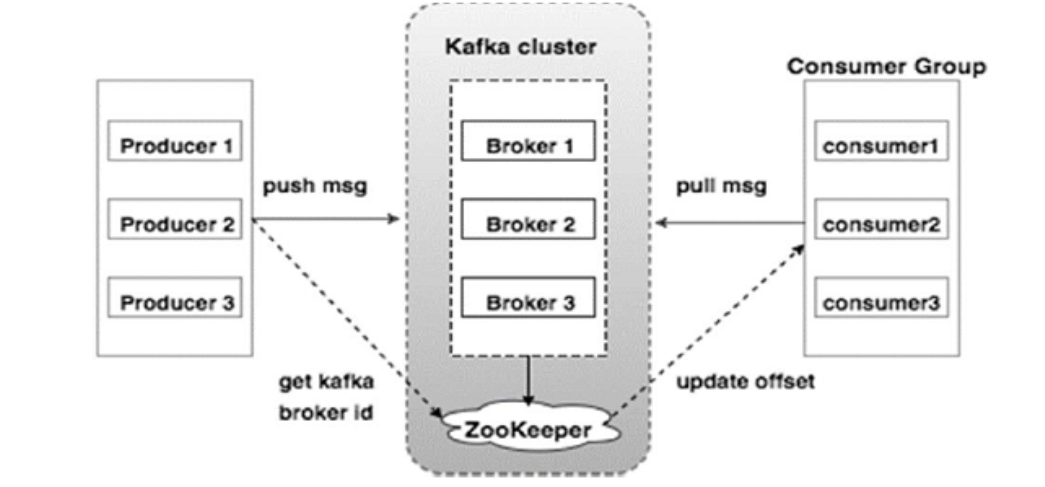
Kafka主要组成部分:
- Broker:kafka集群的服务器,类似于node的概念,一个broker上可以有多个topics
- Topic:每条发布到kafka的消息都有一个类别,这个类别就是topic
- Commit Log:由message,offset等组成
- Producer:生产者,向broker发消息
- Consumer:消费者,从broker取消息
- offset:在partition中的每条信息都会被分配一个唯一的顺序id叫做offset,consumer会track这个offset
- Partitions:topics在物理上的分组,每个topic可能分成多个partition,每个partition都是有序的队列,kafka只保证一个partition的顺序,而不能保证partition间的顺序,具体消息会到哪个partition,由hash算法或者round robin决定
- Zookeeper:用来存储和维护集群配置信息,选举算法和集群切换;在0.8以前还支持追踪offset,后面被取代
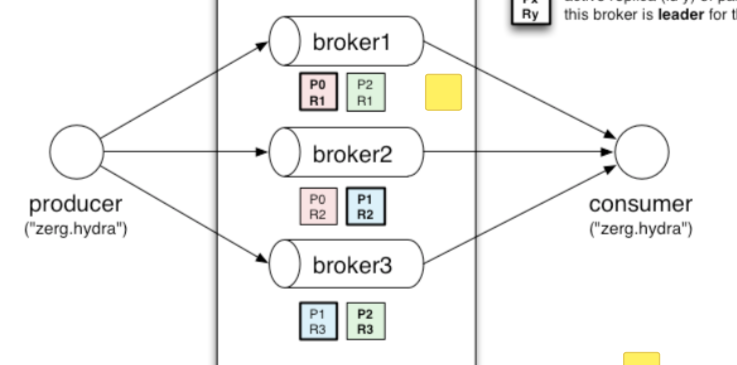
在这个图中只有一个topic:zerg.hydra,它包括三个partition,分别是P0,P1,P2,每个partition在不同broker上又有replication,这里每个partition有3个replica,但其中只有一个是leader(图中边框加粗),对这个partition所有的读写只能走leader,针对每个partition的读写都可以并发进行。
Kafka特性
保证:
- kafka保证了每个topic的partition的内容会按照其发送的顺序增加
- consumer看到信息的顺序和其存储在log中的顺序相同
- 如果想保证全局顺序,有两种方案:只使用一个parttion;在consumer应用中增加全局顺序的处理(例如在storm的topology中)
消息传递:
At Least Once(default):消息不会丢失但可能被多次递送,为了做到这个,需要满足:
- 在发送信息的时候保证信息的持久性
- 在读取信息时保证持久性
- produce发送但没收到ack时->检查最近的commit值
- consumer要保存offset
消息传递的方式:
- 消息广播:把消息发送给所有consumer
- 订阅发布:消息发送个单个consumer
通过consumer group的方式实现
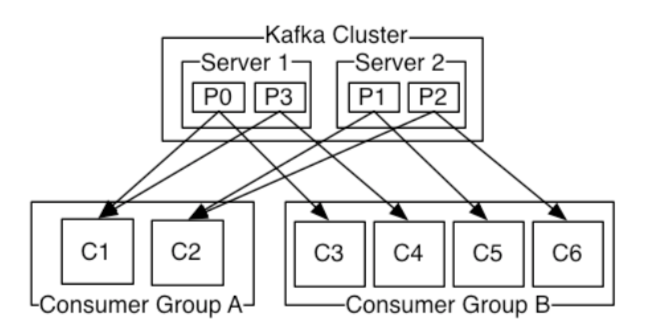
对于订阅发布,每个consumer对应一个独立的consumer group即可,而对于广播,则可以把所有的consumer放在一个consumer group里。不论每个group里有多少个consumer thread(小于等于partitions),对应多个partition,这个consumer thread总会消费全部的partition。因此,最好的设计便是consumer group下的thread与partition数量相等,这样效率最高。
发送信息:
- 可以选择同步/异步,同步在发送时会进入阻塞,异步可以实现高吞吐率
- 异步时将信息batching化
- 当queue满之后异步producer可能造成消息的丢失
发现leader:
- producers:不与zookeeper直接接触,而是通过bootstraping的方式,让boostrap server(broker)通知producer有哪些存活的broker以及如何找到对应的partition leader。而boostrap broker是通过zk来知道的。
Rebalancing:
每个topic的partition对应的conusmer是在运行时动态分配的,这个过程会造成rebalancing(因为机器会坏或者consumer会因为一些原因挂掉)会发生rebalance的情况包括:
- consumer加入或离开consumer group(例:通过createMessageStreams()为topic注册consumer)
- broker加入或离开(例:当broker无法发送heartbeat给zookeeper)
- topic由于filter而造成的 ”加入/离开“
为什么kafka那么快?
- Zero Copy的使用:即使用sendfile()系统调用代替了传统I/O中的read()和write(),使数据由MDA从磁盘直接读取到内核buffer中,然后从内核buffer直接复制到socket buffer(而不用从kernel buffer->application buffer->socket buffer),减少了其中的copy和上下文切换
- I/O过程中batch化数据
- 串行硬盘写入
- 大量依赖linux PageCache(页缓存):自动使用机器上的所有可用内存
- 可扩展性强
注意:
每次启动kafka前需要先启动zookeeper,kafka和zookeeper都需要在每台机子上都运行start程序(不同于hdfs)